Distributed infrastructures are always difficult to monitor. You have to get on multiple nodes to check for multiple logs get sometimes get deleted too soon.
A centralized log ingestion and management platform is a must for the System-Engineer-Who-Doesn’t-Want-To-Get-Crazy.
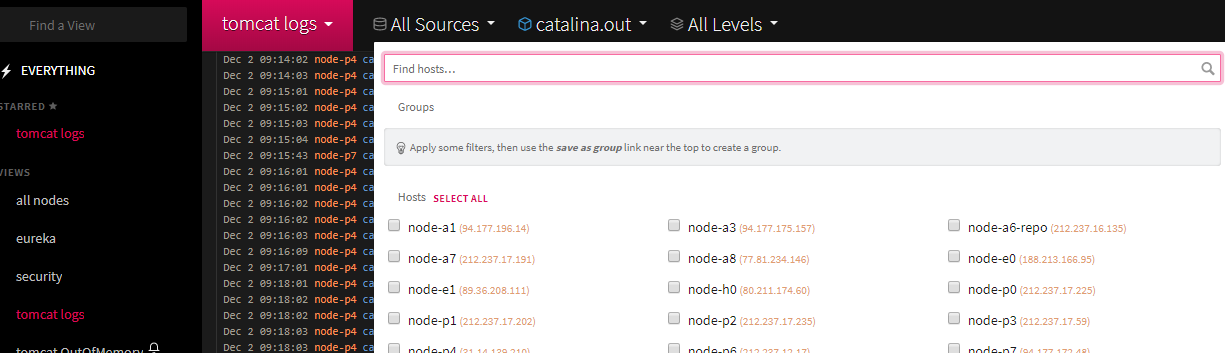
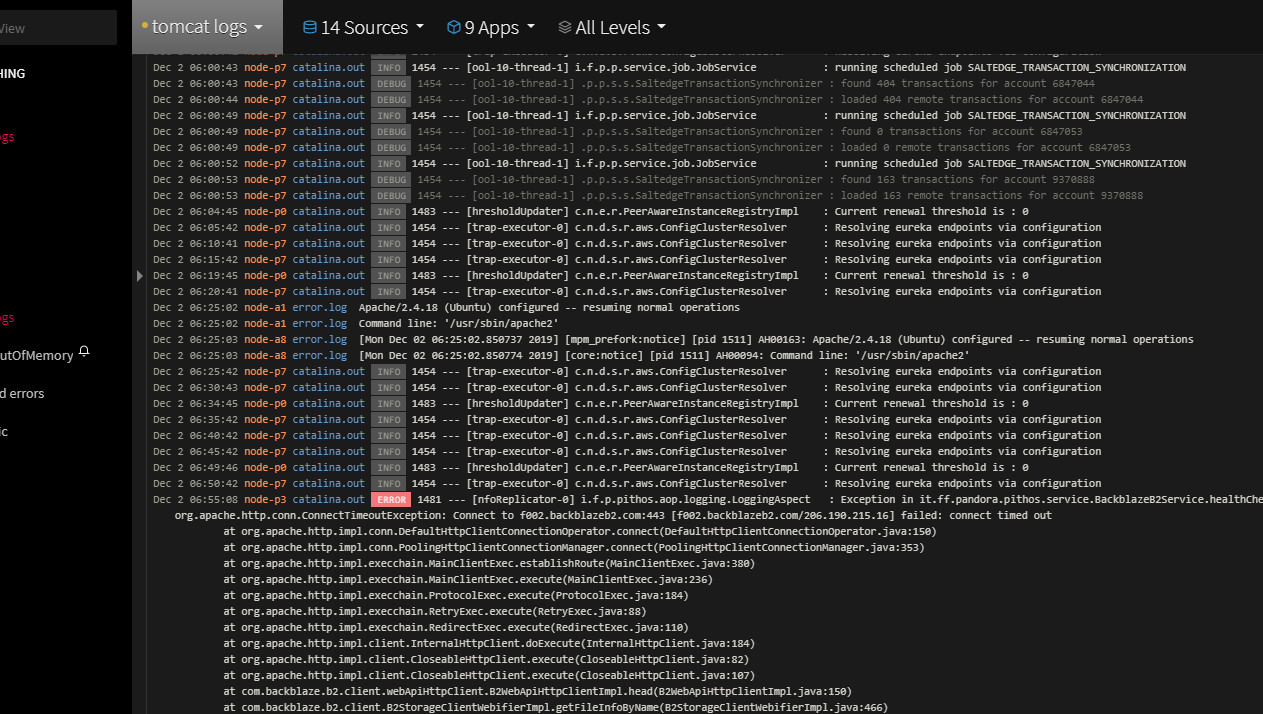
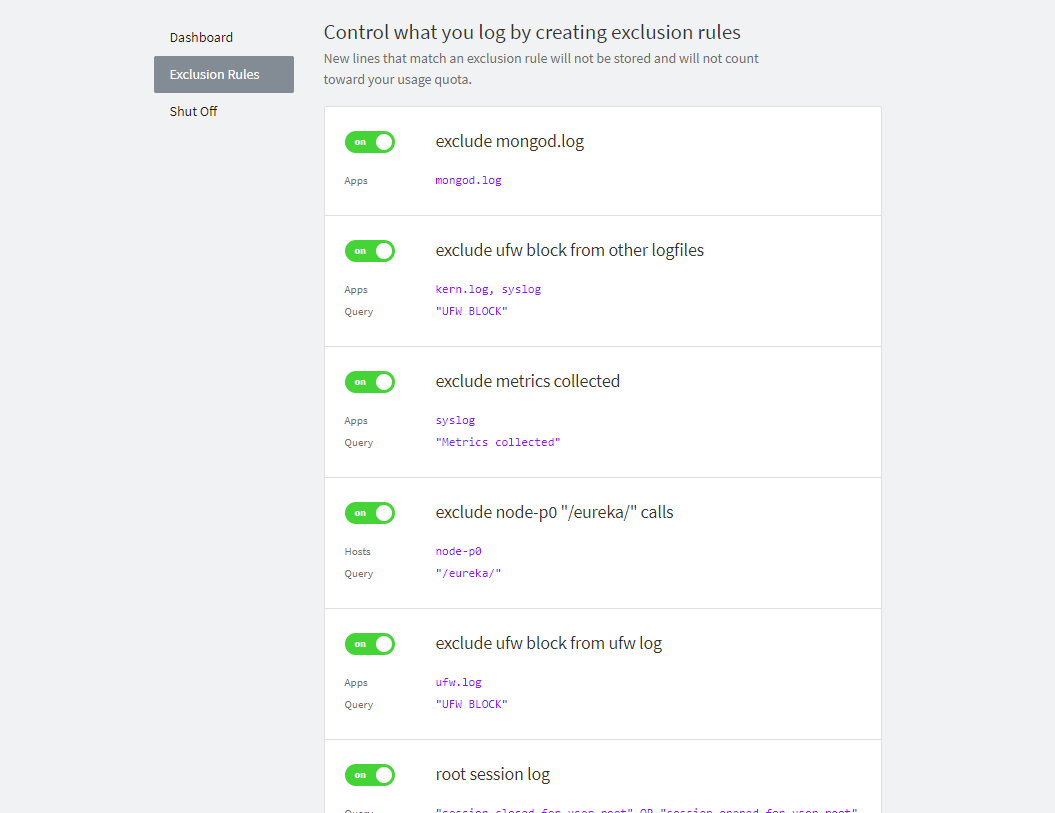
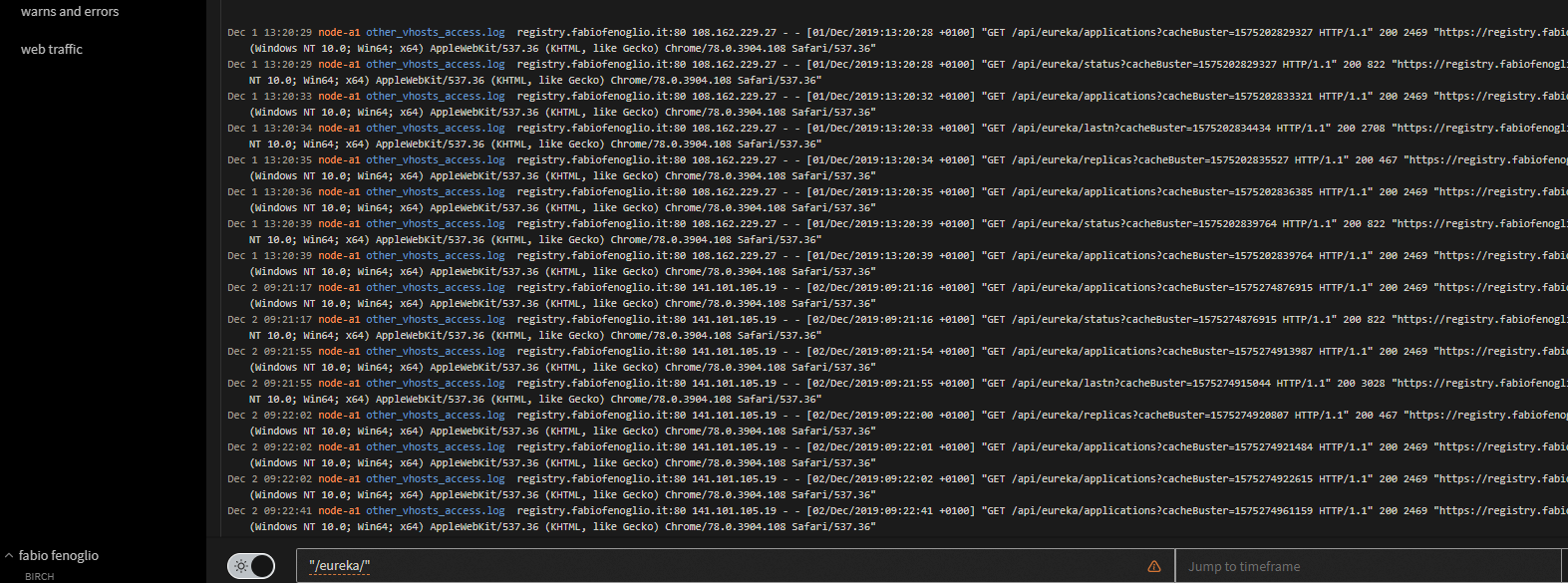
What is this ?
LogDNA is a centralized log ingestion, management and monitoring platform.
It ingests logs from multiple systems, stores them, analyzes them, alerts you, lets you search, lets you customize ingestion and so on.
Why did I do this ?
To not go crazy.
Logs are stored in different files.
In different nodes.
And you must cross them and read from different files and systems in chronological order.
What the hell, seriously.
How did I do this ?
To configure centralized log ingestion I just had to
- sign up to the service
- give them my credit card details and cry (there is a free plan as well!)
- install the agent on all nodes (available for CentOS, Debian and Ubuntu server nodes)
- configure log ingestion to avoid excessive log from unwanted origins
- configure dashboards filtering by node and application
- configure alerting policies (eg. “Alert me in case you see an OutOfMemoryError”)
The pay-per-use plan is very cheap and stars from 3$/month.
How would this be instrumental in a business environment ?
Log management and debugging-from-logs are very widespread activities that we must perform everyday.
Log management would be life changing if applied in the right way on the right systems.
Can I test this?
You can test the application at LogDNA but I can’t give you access to my account because of security reasons. Write me an email and I will happily discuss it with you.