Real time monitoring of application services is a critical topic.
Whatever the context may be, detecting system failures in near-real-time is key to SLA compliance and deep knowledge of the most critical failure points is one of the best way to provide a solid and reliable infrastructure.
Because of this reason, I always set up redundant monitoring and alerting systems for the infrastructures I manage.
My tool of choice for application-level monitoring is UptimeRobot.
What is this ?
UptimeRobot is a free to use application level monitoring service.
Why did I do this ?
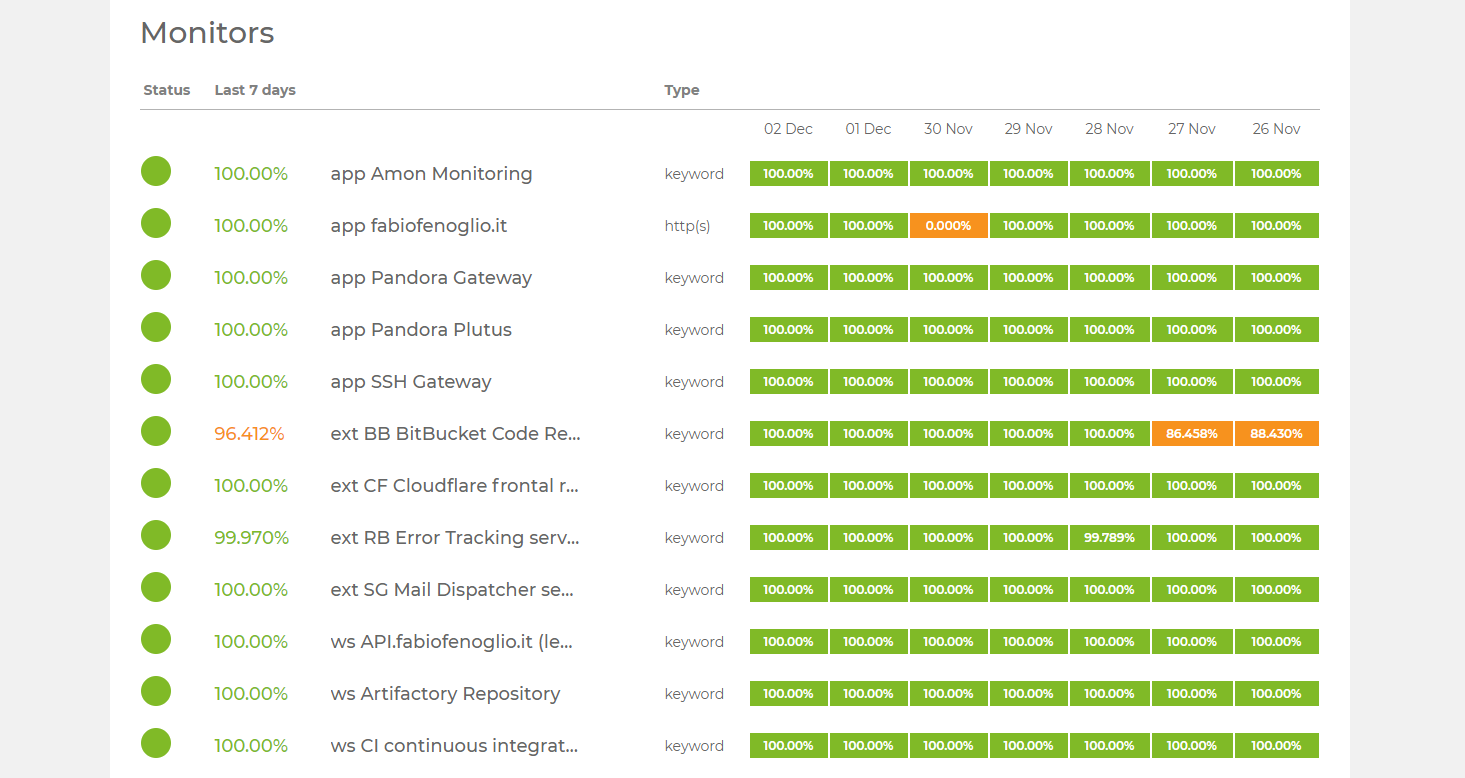
Service availability monitoring is very important and should always be provided, for every service, along with per-node resource monitoring.
How did I do this ?
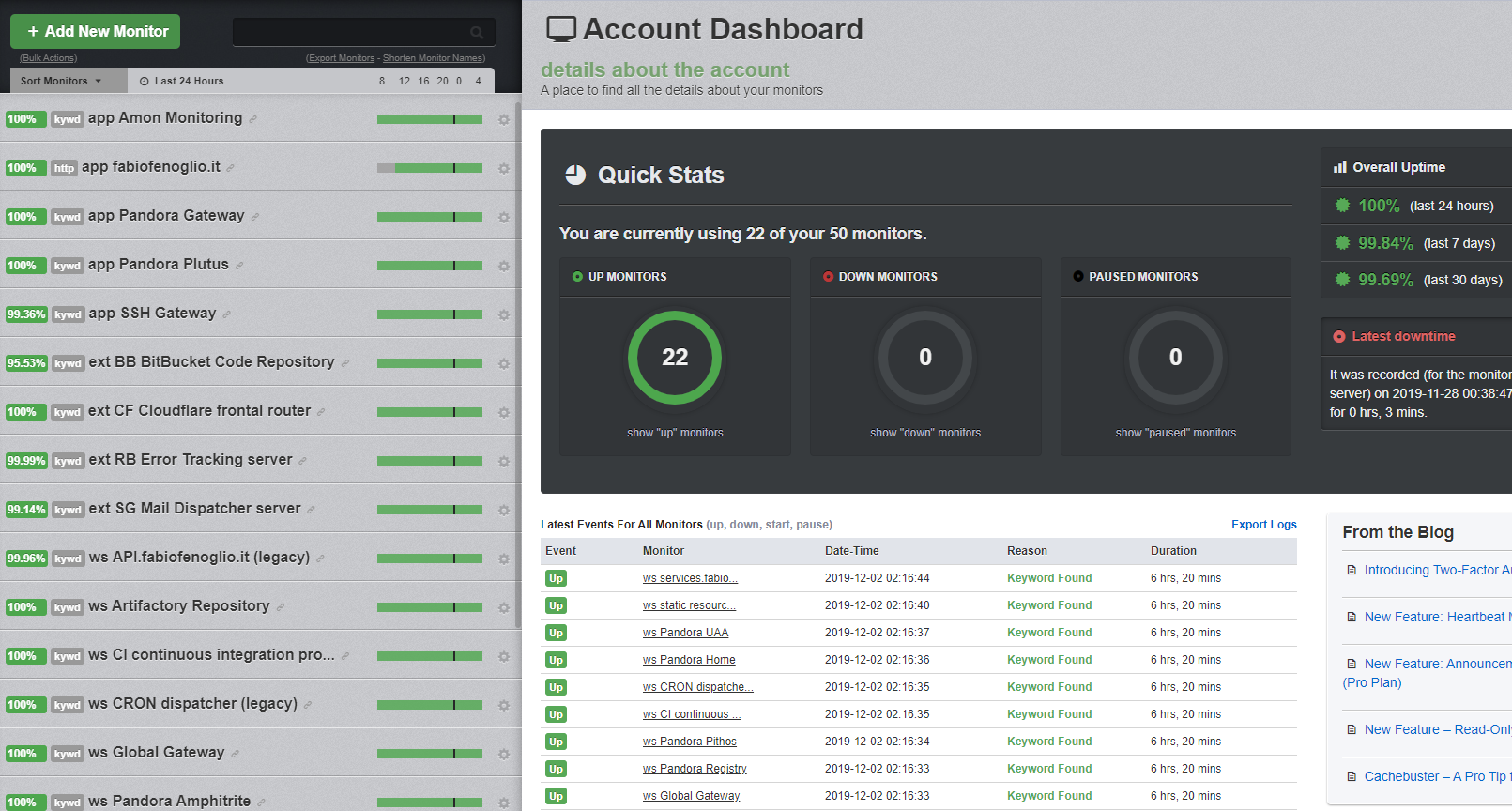
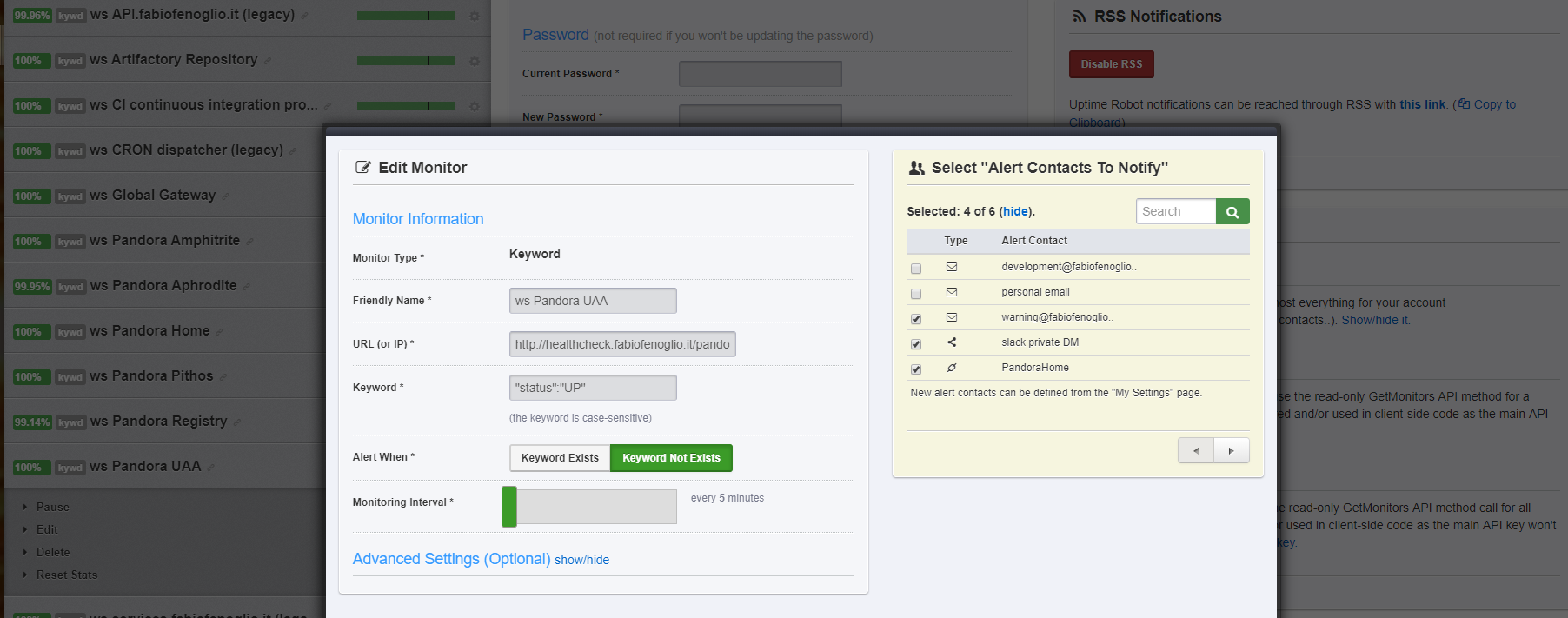
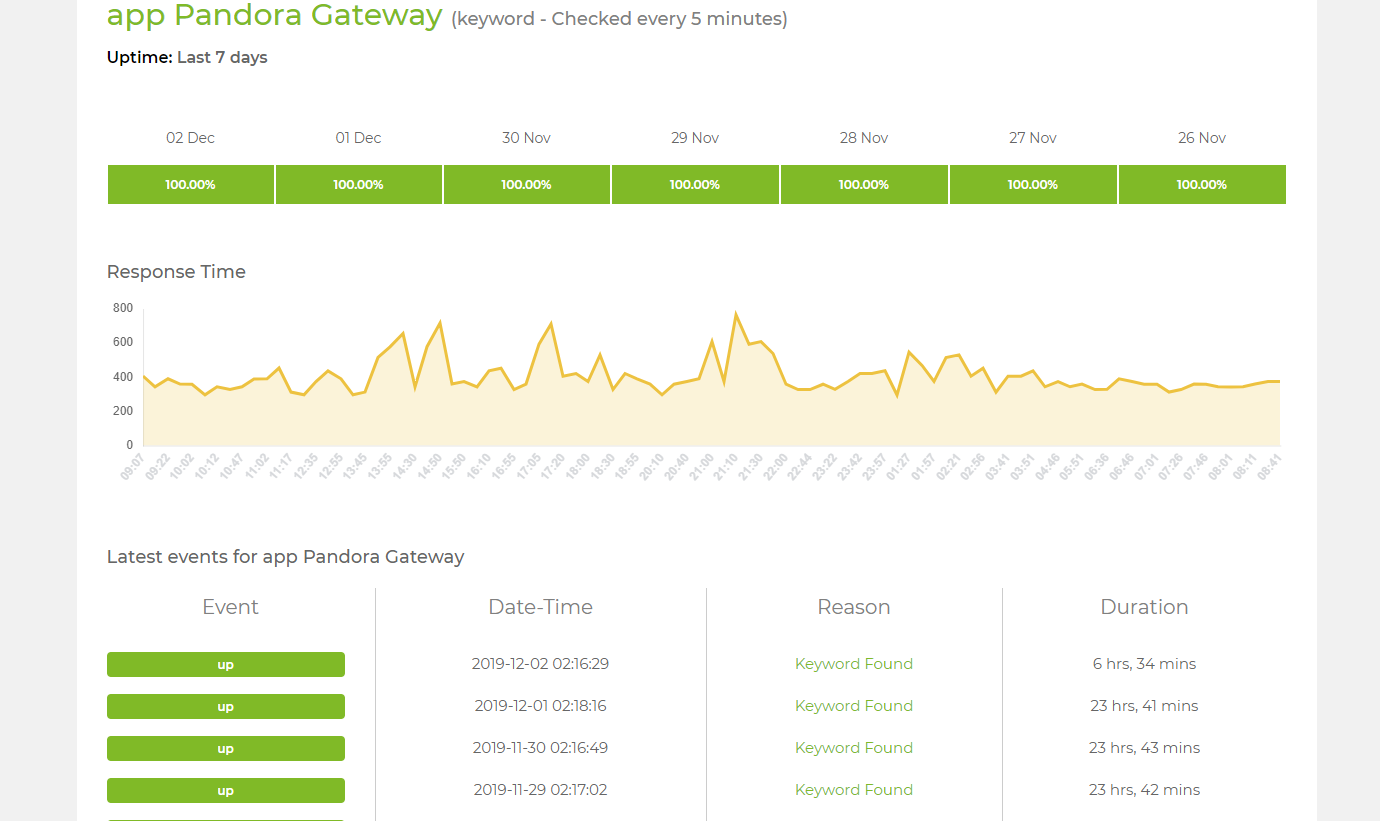
UptimeRobot is an online service where I configured every monitorable application. It pings your endpoints every 5 minutes and alerts you if something is wrong.
Allowed policies are HTTP status code check, Keyword presence/absence check, PING execution.
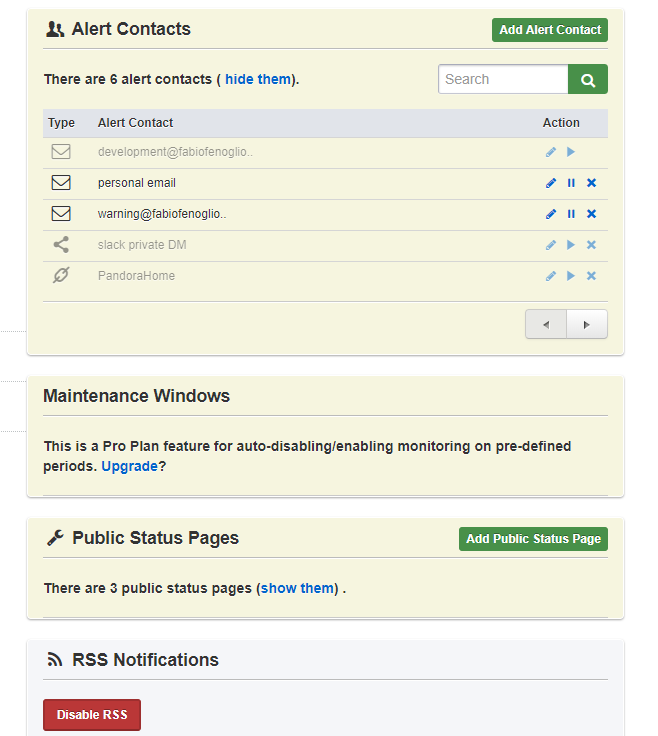
Alerting is configured via email, Telegram BOT and custom webhooks (the lights of my living rooms literally blink of red when something is going wrong in my systems - and yes, my girlfriend is quite mad at me for this).
Access to status dashboard is public to be displayed on public monitors (eg. Home TV for notification failures, or Google Hub displays).
How would this be instrumental in a business environment ?
Setup of this kind of systems gave me a better understanding of application-level monitoring policies and monitoring channels management.
Can I test this?
You can test the application at uptimerobot.com but I can’t give you access to my account because of security reasons. Write me an email and I will happily discuss it with you.