Real time monitoring of IT infrastructures is a critical topic.
Whatever the context may be, detecting system failures in near-real-time is key to SLA compliance and deep knowledge of the most critical failure points is one of the best way to provide a solid and reliable infrastructure.
Because of this reason, I always set up redundant monitoring and alerting systems for the infrastructures I manage.
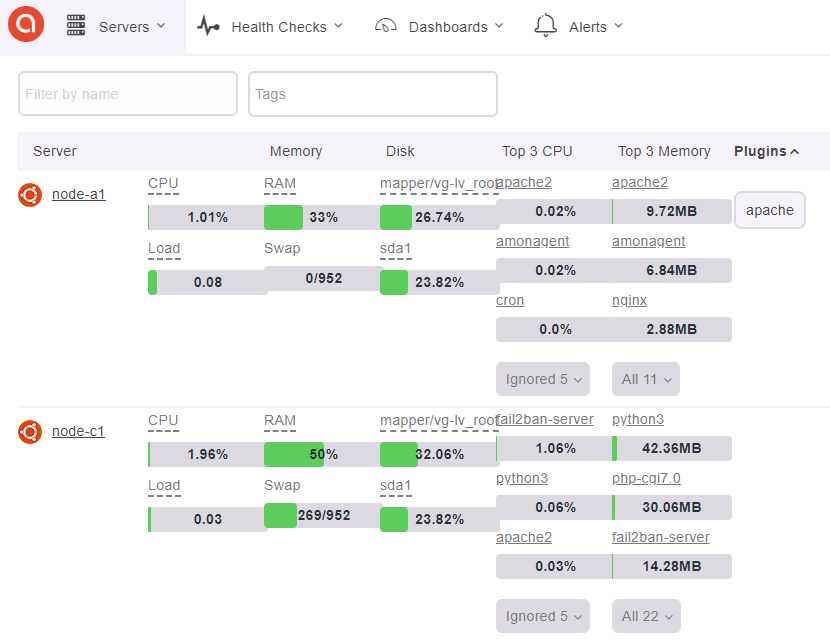
My tool of choice for nodes and resources monitoring is Amon.

What is this ?
Amon is a modern, open-source server monitoring platform.
Why did I do this ?
Given the importance of resources monitoring in providing a reliable service, particular attention should be given to resource monitoring.
While other tools surely provide a much better coverage regarding application-level monitoring, they usually fail in monitoring low-level resources: this leads to a late alerting where it is usually too late to avoid service disruption. This tools fills that void, providing low-level resource monitoring and alerting as soon as possible, before critical problems have the time to arise.
How did I do this ?
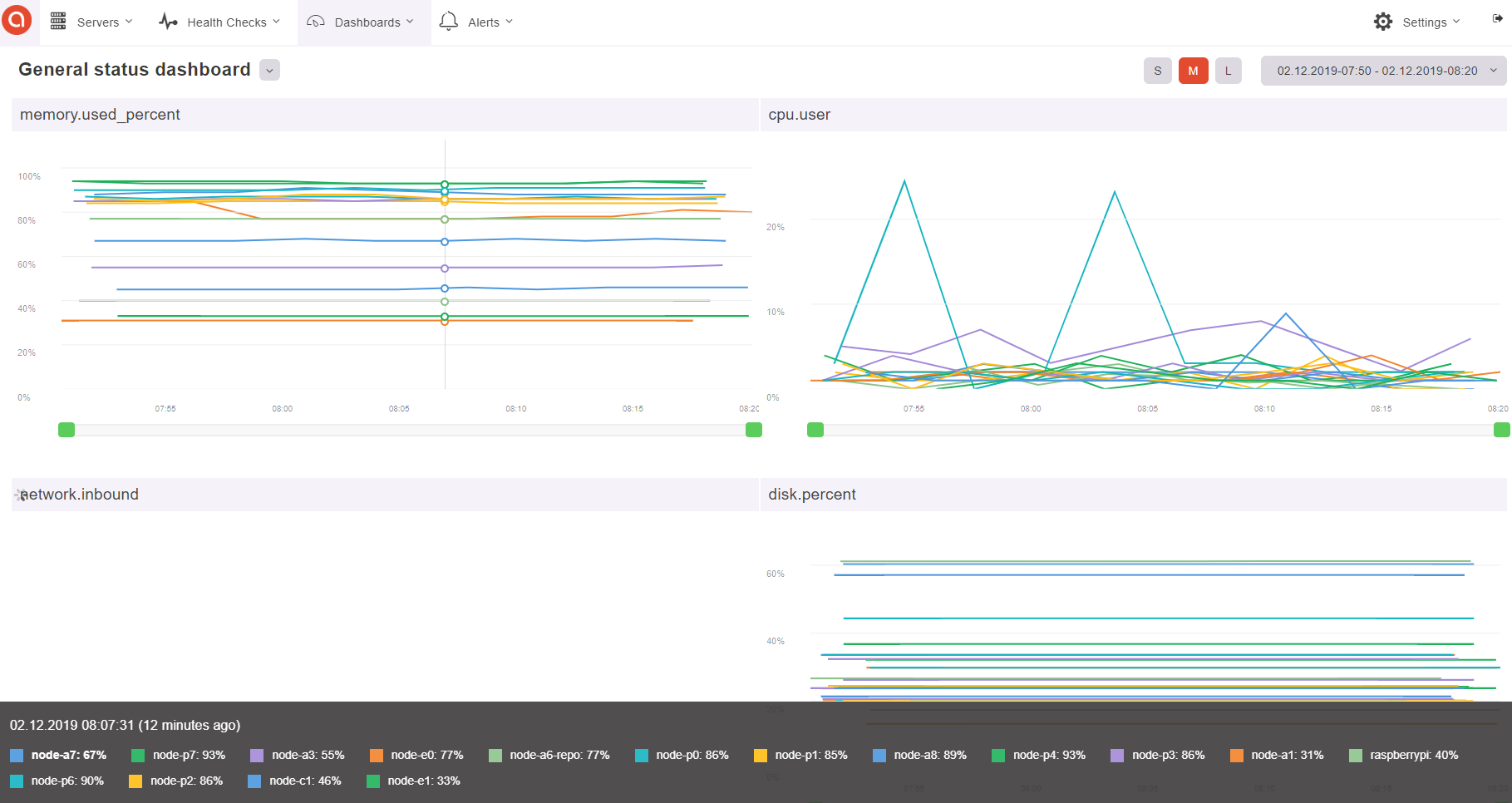
A dedicated monitoring node with a fine performance-tuned mongoDB database hosts the monitoring server.
Every other VMs or physical node gets configured with a metric collecting agent that forwards information to the central server.
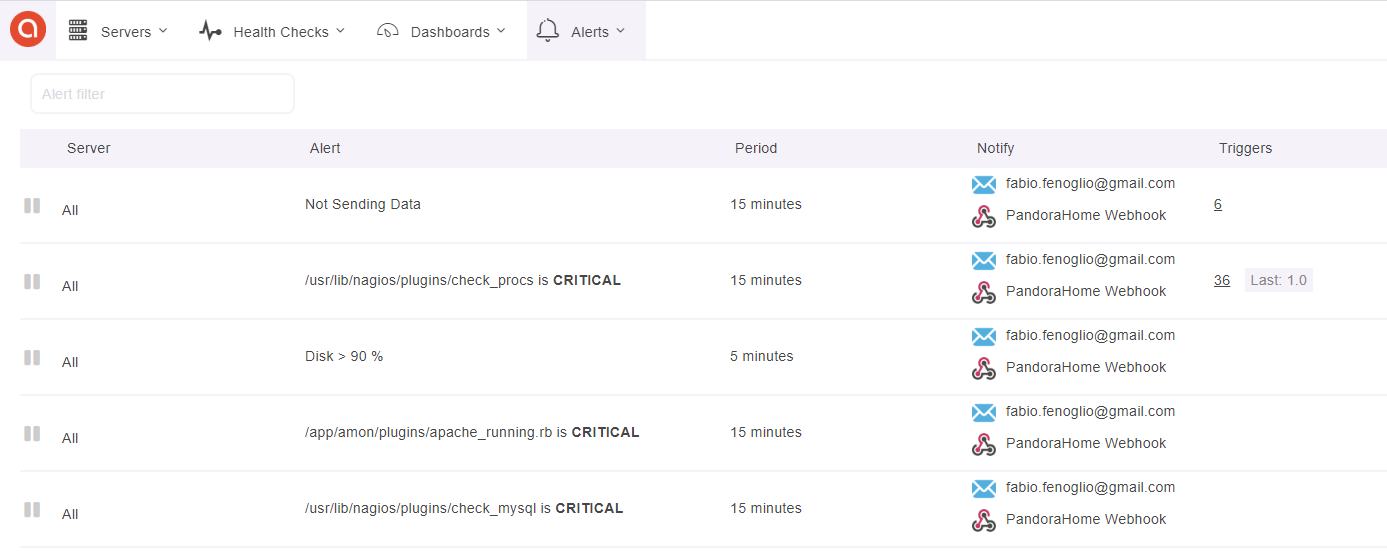
Alerting policies are setup to detect critical RAM shortages, full disks, missing processes and other similar problems.
Real time notifications are sent via email, pushover notifications, Telegram BOTs and custom webhooks (the lights of my living rooms literally blink of red when something is going wrong in my systems - and yes, my girlfriend is quite mad at me for this).
Access to status dashboard is public to be displayed on public monitors (eg. Home TV for notification failures, or Google Hub displays); access to the backend is protected by SSO under CloudFlare Access policies.
How would this be instrumental in a business environment ?
Setup of this kind of systems gave me a better understanding of failure points and significantly improved my failure prevention spider senses.
I strongly believe that getting my head deeply in the infrastructure monitoring topic also served in gaining more resource-conscious development and design skills.
Can I test this?
You can require access to the application at monitoring.fabiofenoglio.it by writing me an email.